

If you have been following this blog series, you know that I’m exploring HPE SimpliVity architecture at a detailed level, to help IT administrators understand VM data storage and management in HPE hyperconverged clusters. Now we are getting to the good stuff! Options for day-to-day operations.
In the first blog I explained how data of a virtual machine is stored and managed within an HPE SimpliVity Cluster. In Part 2 I explained how the HPE SimpliVity Intelligent Workload Optimizer (IWO) works and I detailed how it automatically manages VM data in different scenarios.In this Part 3 post, I will cover further options available for provisioning VMs in HPE SimpliVity environments. This article will describe the interactions between IWO and VMware DRS and how admins can manage this interaction in regards to data placement if required.
Understanding the finer points of initial placement
Now that I have made the mechanics of initial placement of data clear from the previous posts, let’s explore some of the finer points and interactions between DRS and IWO.
‘Automatic management of data’ and ‘zero touch infrastructure,’ is all well and good, I hear you say, but what if you, as the administrator, want more granular control over your infrastructure?
Firstly, VMware DRS does not have access or awareness of underlying storage utilization, nor is it even designed with this in mind. Its only concern is keeping the CPU and Memory resources of the cluster balanced as a whole. However, the HPE SimpliVity platform must take storage and available IOPS into account when placing data and, perhaps even more importantly (as we covered in Part 2), it looks to place similar workloads together to maximize de-duplication rates.
For those reasons, the HPE SimpliVity platform may place the primary and secondary data containers for a VM on nodes other than the nodes VMware DRS chooses. What options are available to control this behavior? Let’s try to tease this apart.
We know the following to be true: If set to fully automatic, VMware DRS will make a placement decision based on available CPU and memory resources of the cluster. The HPE SimpliVity platform (through the Resource Balancer Service) may or may not honor these placement decisions based on its own placement algorithms of available capacity, available IOPS and VM type – specifically HPE SimpliVity clones, VMware clones (if the VAAI plugin is installed) and VDI. From there IWO creates affinity rules for these VMs and pushes these rules to vCenter. As a result, VMware DRS will be forced to ‘obey’ these new rules by performing v-motions to the new correct host.
These new rules could potentially cause a resource imbalance https://www.mathos.unios.hr/mc/ in the cluster in terms of CPU and memory utilizations, as DRS has chosen an optimum node which could be ignored, and vCenter is aware of that possibility.
VMware DRS evaluates your cluster every 5 minutes. If there’s an imbalance in load, it will reorganize your cluster. If this scenario is indeed encountered, DRS will re-calculate overall cluster resources and may move other VMs (according to their affinity rules) to re-balance cluster load. This process is dynamic both from a HPE SimpliVity and VMware DRS point of view, so while a particular VM created (or migrated) to an HPE SimpliVity cluster may be placed elsewhere, DRS can re-balance the cluster by moving other VMs to redistribute resources. This is often what we see in such scenarios.
The HPE SimpliVity DRS rules are ‘should’ rules and thus during an HA event such as I just described, this rule will be ignored in order to keep the VMs running. ‘Should’ rules will also ignore DRS affinity rules in scenarios where a single host is extremely over-utilized. For its part, DRS makes a best effort to optimize according to existing affinity rules created by IWO, but in some high load environments, DRS will ignore affinity rules populated via IWO. This can result in VMs running on a node other than their primary or secondary storage nodes.
We will discuss the merits of data locality, but first let’s explore the placement algorithms of the Resource Balancer Service.
Resource Balancer placement algorithm
By default, the Resource Balancer Service uses the BALANCED placement algorithm for initial VM placements (existing VMs transferred into the system) and the BEST_FIT for provisioning new VMs. BEST_FIT and BALANCED consider Storage Capacity and I/O demand of all nodes in the cluster when deciding where to place the primary and secondary data containers. CPU and memory are currently not considered. (I outlined the Resource Balancer placement algorithms for each VM type in my previous post.)
For each replica (secondary data container of the virtual machine) the following algorithm is applied:
- The node with lightest IOPS workload is chosen for placement, provided it meets the storage utilization constraint
- If all nodes violate the constraint, it will choose the node that violates the constraint by the smallest amount
For batch VM deployment:
- If several nodes have the same score, the placement node is chosen at random
- Data container replicas follow the same algorithm
- The node on which VM is deployed does not play a special role
Issue the command “dsv-balance-show –status” to view the status of Resource Balancer.

Disabling the Resource Balancer
The Resource Balancer can be disabled on a per node basis if required. When Resource Balancer is disabled, the VM provisioning algorithm will now be set to RANDOM and LOCAL_PRIMARY. This essentially means one of two things:
- DRS set to manual – If the user selects a node to house a VM from vCenter, the Resource Balancer will not choose a better node to house its data (as it is offline).
- DRS set to fully automatic – If virtual machines are being created at the cluster level within vCenter, data containers are provisioned on a round robin basis as chosen by DRS. Again, the Resource Balancer will not choose a better node (as it is offline).
Resource Balancer can be disabled on the node using the command “dsv-balance-disable”.
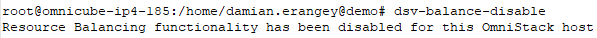
Enabling the Resource Balancer
The Resource Balancer Service can be re-enabled by the command “dsv-balance-enable”. Once re-enabled the Resource Balancer will default back to BEST_FIT and BALANCED for that node.
IWO operations
A cluster must contain three HPE SimpliVity hosts (previously known as HPE OmniStack hosts) to start creating cluster groups and affinity rules in DRS. A one- or two-host cluster automatically accesses data efficiently and does not need affinity rules.
When you first deploy an HPE SimpliVity host, the IWO setting defaults to enabled. If you deploy an HPE SimpliVity host to a cluster that contains other HPE SimpliVity hosts, IWO defaults to the setting used by the cluster. For example, if you changed the setting from enabled to disabled, the HPE SimpliVity host joining the cluster takes on the disabled IWO setting.
You can also include standard ESXi hosts if they share an HPE SimpliVity datastore with another HPE SimpliVity host in the cluster and the HPE SimpliVity VAAI plugin is installed.
Disabling IWO
Unlike the Resource Balancer Service, disabling IWO is a cluster wide operation not a node local operation.
Disabling IWO will remove all HPE SimpliVity affinity rules from vCenter as outlined below.
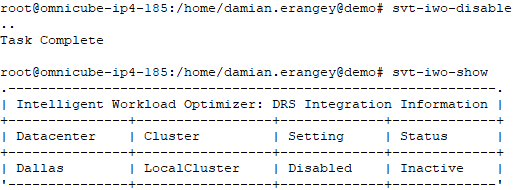
To disable IWO issue the command “svt-iwo-disable”
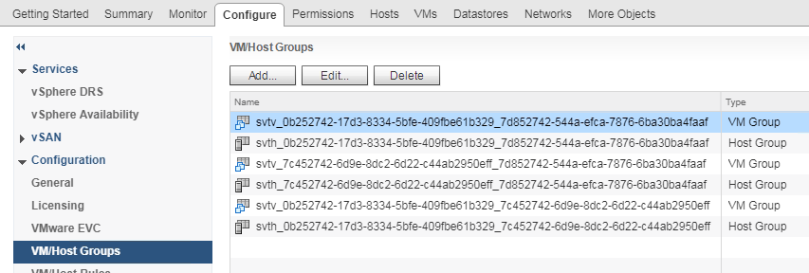
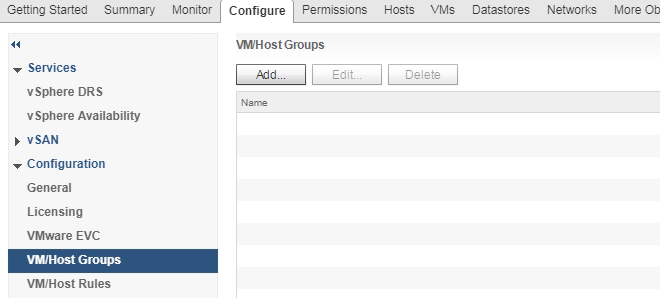
Enabling IWO
IWO can be re-enable using the command “svt-iwo-enable”.
Once re-enabled DRS rules are automatically re-populated back into vCenter.
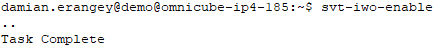
Checking the status of IWO
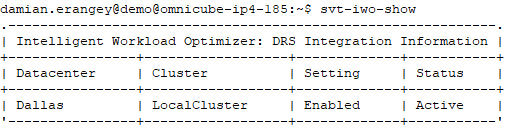
Use the command “svt-iwo-show” (from any node within the cluster) to show if a cluster has Intelligent Workload Optimizer enabled or disabled. This will determine whether the feature is active or not.
Data Locality
Data locality plays an important role in your decisions as to the best approach for your particular data center.
As previously discussed, it is possible and supported to run virtual machines on nodes that do not contain primary or secondary copies of the data. In this scenario, I/O travels from the node over the federation network back to where the primary data container is located. This is called I/O proxying.
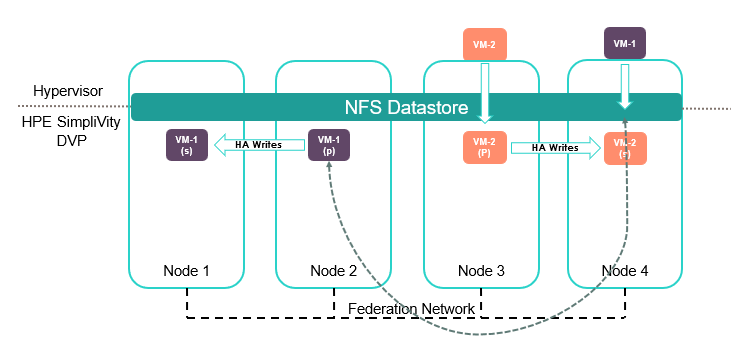
By default, and as outlined through the creation of DRS affinity rules, the HPE SimpliVity DVP is configured to avoid virtual machine I/O proxying. You can run virtual machines in this configuration by either disabling IWO or setting DRS to manual. Typically, this will add 1 to 2ms of round-trip time above the baseline I/O latency. This may or may not be a concern depending on the performance requirements of the virtual machine workload.
An HPE SimpliVity alert “VM Data Access Not Optimized” will be generated at the VM object layer within vCenter, however this notification can be supressed.
Sharing HPE SimpliVity datastores with standard ESXi hosts
You can share HPE SimpliVity datastores with standard ESXi hosts (hosts without HPE OmniStack software). Configuration of access nodes is beyond the scope of this post, however you can find information here.
Essentially, you need to specify the storage data transfer IP address that you want the standard ESXi host to use. To do this, you must know the network IP address of the HPE OmniStack Virtual Controller (OVC) virtual machine you plan to use to share the datastore. For example, the HPE SimpliVity host provides two potential paths:
- The Storage Network IP address (recommended as it provides redundancy and 10GB access)
- Management Network IP address (also supported but provides no redundancy and only 1GB access)
Your desired network also impacts the IP address. If you use the switched method for the 10 GbE storage network, use the Storage Network IP address of any HPE OVC. It is a best practice to use this network because it provides higher bandwidth and failover capability.
If you use the direct-connect method for the 10 GbE storage network, specify the Management Network IP address of the HPE SimpliVity host. However, this network has no failover capability.
Note: The standard ESXi host can reside in the same cluster as the HPE SimpliVity host and datastore you plan to use, or in another cluster within the same datacentre for greater flexibility.
As illustrated below, Node 5 is a standard ESXi host, it has been configured to communicate with the storage IP of the OVC on Node 4 (as the OVC handles the NFS traffic). This means the OVC on Node 4 has now exported the desired NFS datastore to Node 5 via the 10GB network.
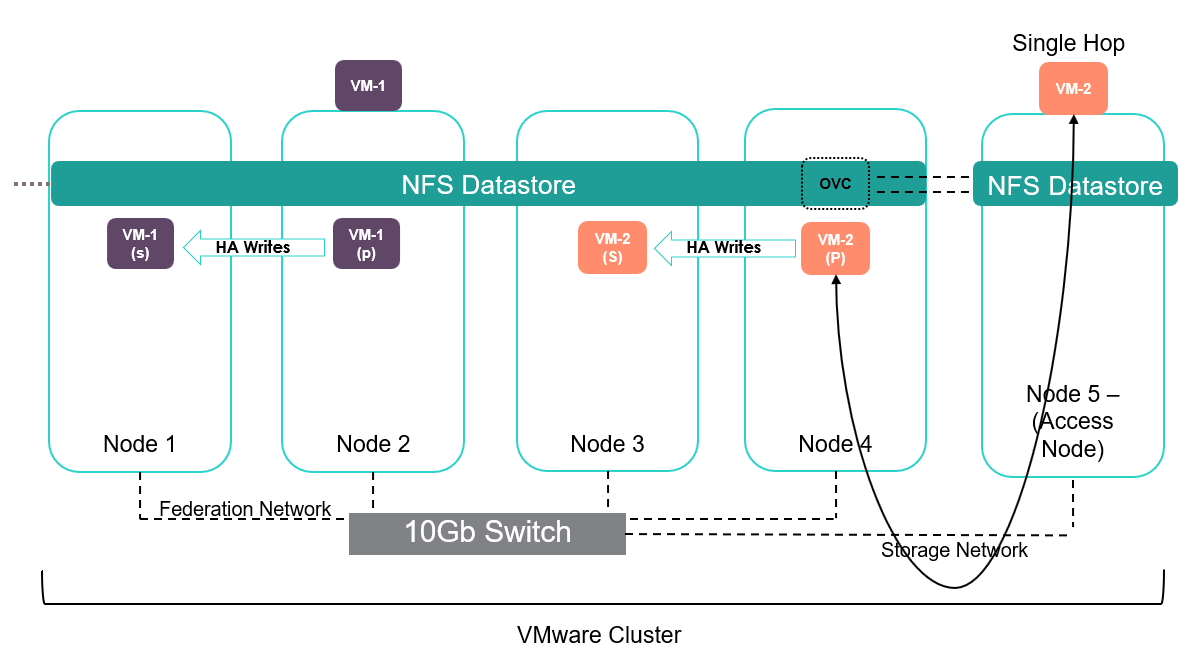
Configured access nodes do not have data locality by their very nature. All traffic will flow via the 10GB or 1 GB back to the Node it is configured to communicate with.
When you allow a standard ESXi host access to an HPE SimpliVity datastore by sharing it with an HPE SimpliVity host, you can:
- Use vSphere vMotion to migrate virtual machines that run on a standard ESXi host to another host in the federation with no disruption to users.
- Use vSphere Storage vMotion to migrate virtual machines to a HPE SimpliVity datastore with no disruption to users
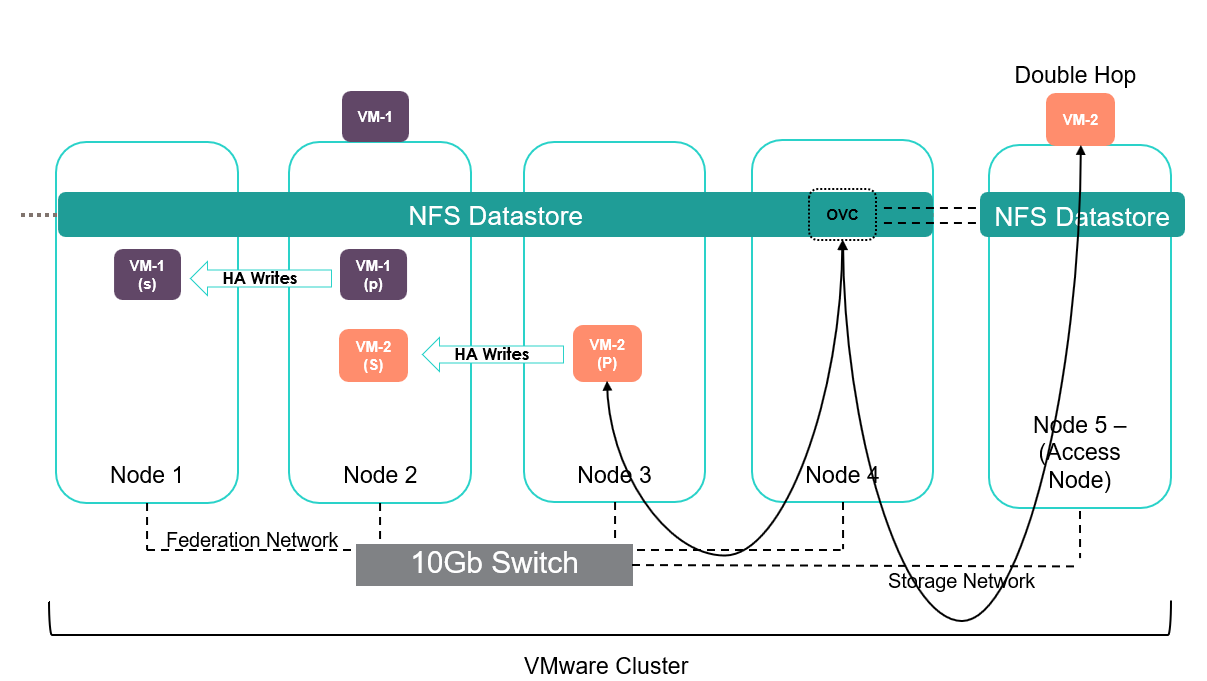
Avoiding the ‘double hop’ scenario
Be sure to configure NFS access to the standard ESXi server from the HPE SimpliVity node that contains the local copy of the data you are serving to avoid double hopping over the network which would add further latency.
The below diagram illustrates the scenario where Node 5 is configured to access Node 4, however Node 4 does not contain a copy of VM-2 data which is running on Node 5. As a result, one further hop is required over the federation network to access a copy of the VM’s data.
Scenarios
Now that I have laid out the available options, let’s look at some scenarios to illustrate these points.
I’ve dealt with many different customer requests and I always start with the same question: What are your priorities? Capacity efficiency, CPU utilization, memory utilization, performance, overhead (over-commit, under-commit), even data distribution, hot standby? If you paint a picture of the desired end goal, it’s easy to work with the HPE SimpliVity platform to achieve this goal. (Client virtualization scenarios and VDI best practices are beyond the scope of this post. Information on this topic can be found at www.hpe.com/simplivity or in this technical whitepaper.)
Scenario 1 – Zero Touch Infrastructure
I want zero touch infrastructure. I have sufficient cluster resources in my environment (CPU, memory, capacity and performance) for all my VMs, however achieving best possible data duplication ratios is a priority to accommodate future growth. I have a mixed workload type. Storage distribution and control over virtual machine distribution and placement are not a concern, and I want VMware DRS and HPE SimpliVity to work together to manage my cluster resources.
If this is the case, set VMware DRS to fully automatic and let DRS choose the best nodes to provision workload based on available CPU and memory cluster resources. As outlined above, the HPE SimpliVity platform may or may not honor this placement decision based on its own placement algorithms of available capacity, IOPS and VM type. If placement matches, then no change. If the nodes do not match, the affinity rules populated to vCenter will force DRS to re-calculate cluster resources. Based off the configured settings, DRS may move other VMs (according to their affinity rules) to re-balance cluster load. This process works for most customers. You are ensuring maximum data deduplication rates while allowing DRS to balance workload within certain constraints.
Scenario 2 – More Granular Control
I want more granular control over the environment. I have 4 nodes in the cluster. This is a new environment, and I want 25% of my VMs on each node, which will ensure each node is correctly utilized in terms of CPU, memory and capacity. I want to control where each VM is placed during provisioning. I have sufficient capacity, and I’m willing to forgo some data efficiency to achieve my goals. Once initial provisioning is complete, I want future workloads to be automatically provisioned.
This scenario might be a bit extreme, but it does give us a chance to explore a few options. Firstly, leaving DRS set to fully automatic would most likely achieve 25% distribution across all nodes, and in most circumstances the HPE SimpliVity platform would follow suit with this storage distribution. However, you stated that you want granular control over which VMs run where. Again, it’s about painting a picture of your goals.
The following should be implemented:
- Resource Balancer should be set to disabled on each node.
- IWO should also be set to disabled.
- DRS should be set to manual.
These settings will allow direct control over where VMs are provisioned. You can now provision VMs manually on each appropriate node to achieve 25% distribution across the cluster. In other words, whatever node is selected within vCenter to house the VM will also be the node that houses the data (the secondary node will be chosen on a round robin basis). No affinity rules will be populated to vCenter (yet).
Note: In this scenario, you stated that deduplication was not a top priority due to sufficient capacity. VMs have simply been provisioned based on the 25% distribution rule. If the Resource Balancer Service had been enabled, it might have chosen nodes with existing data containers to maximize deduplication rates. It is common for cloned VMs to all reside on the same node in order to maximize deduplication rates. This is not the case in this scenario, because we traded possible deduplication gains for desired VM distribution.
Once complete, Resource Balancer and IWO should be re-enabled to ensure that DRS affinity rules are populated into vCenter server. Once complete, DRS should be set to fully automatic. This will ensure future workload is provisioned automatically.
Scenario 3 – Even VM Load Distribution
I want even VM load across my cluster in terms of CPU and memory. Data locality and I/O https://pmsd2.khm.gov.ua/ performance are not top priorities. Most applications are CPU and memory intensive, and adding 1ms to 2ms to I/O trip times will not impact application performance.
In this scenario, IWO can be disabled thus ensuring no DRS affinity rules are populated into vCenter server. Suppressing DRS affinity rules will allow VMware DRS or allow you to directly distribute VMs across the cluster as desired to ensure all VMs are adequately resourced in terms of CPU and memory. The ‘Data Access Not Optimized’ alarm can be suppressed within vCenter server.
Destination url: http://hpecl.co/HG2QAT0